How to read Machine Learning and Deep Learning Research papers
Tips on preparing Literature survey of a field and how to read a ML / DL research papers. The 3 pass method to read ML or DL research papers is discussed.
- Introduction
- Dynamically Expanding field of Deep Learning
- Why to read research Papers
- Literature survey of a domain
- Organization of a Paper
- How to read a Research Paper
- 3 pass approach to read a research paper
- Important Questions to answer
- Conclusion
- References
Introduction
How to read a research paper, is probably the most important skill which any one who is into research or even anyone who wishes to be updated in the field with latest advancements has to master. When someone thinks of starting out in a domain, the first advice that comes is to look for relevant literature in the domain and read papers to develop an understanding of the domain. Papers are the most reliable and updated source of information about a particular domain. A research paper is a result of days of brainstorming of ideas, and structured and systematic experimentation to express an approach.
But why is reading papers considered such an important skill to be learnt ? Why is even reading papers necessary ? Let’s take on some motivation as to why is reading papers important to keep-up with the latest advances.
This article is the summary of a talk that I delivered for the Introductory Paper Reading Session generously supported by Weights and Biases whose recorded version can be found here and slides can be found here.
Dynamically Expanding field of Deep Learning
The field of deep learning has grown very rapidly in the recent years. We can quantify growth in a field by theh number of papers that come up everyday. Here is an illustration from one of the studies by ArXiv which is one of the platform where almost all of the papers, whether published or unpublished are putup.
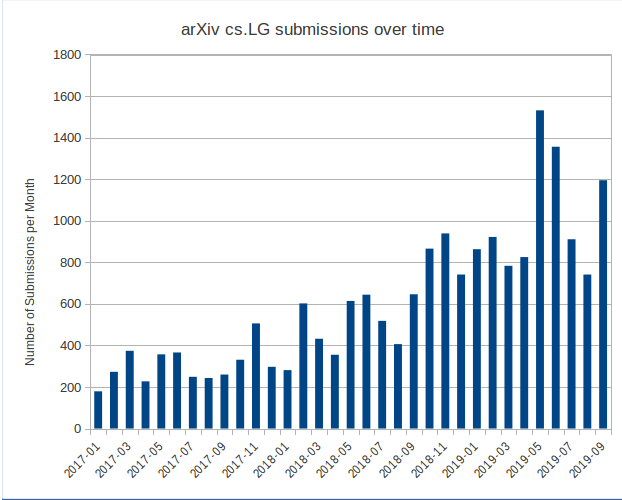
From the figure we can see that the average no of papers has grown to 5X averaging from 300 papers per month in 2017 to around 1500 papers per month in 2019. The figure would probably be close to or above 2k papers per month in 2021. This is a huge number of papers coming up everyday. This shows how dynamic the field is at the current time and it is just growing exponentially in terms of number of papers and amount of new ideas and experiments coming up everyday.
Let’s look at another figure from another study by arXiv
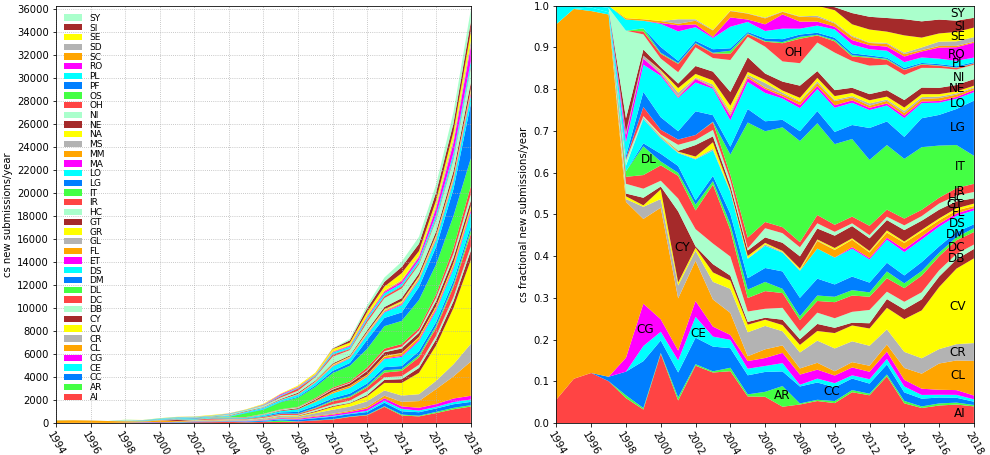
From the figure, the number of papers in the field of Computer Science has grown like a step exponential curve and we see that around 36k papers come out each year out of which around 24k of them as we saw in the previous section are in the field of ML and DL. We can also see in both the figures that the DL field in Green and CV in yellow are among the dominant areas in terms of percentages of papers coming out every year since the early 2000s while the field of CV has grown and opened up a lot after 2012 probably when the prominent work on Image classification by deep networks showed significant performance. These studies definitely speak how fast the field of computer Science is growing and amongst it, how the sub areas related to Machine Learning and Deep Learning are evolving too.
I hope these give a good idea of how fast the field has been evolving and would continue to evolve even faster in the future. But in this fast evolving field, How can we keep up with the pace and develop a expertise in the field ?
Quoting Dr. Jennifer Raff,
To form a truly educated opinion on a scientific subject, you need to become familiar with current research in that field. And to be able to distinguish between good and bad interpretations of research, you have to be willing and able to read the primary research literature for yourself.
Why to read research Papers
- To have a better grasp and understanding of the field: For a particular field, there may be a lot of video lectures and books but with the rate at which the field has been growing, no book or video lecture can accomodate the latest information as soon as they get published. So research papers provide the most updated and reliable information in the field.
- To be able to contribute to the field in terms of novel ideas: When we start working in a field, the first thing that we are advised to do is to do an extensive literature survey, going through all of the latest papers that have come up in the field till date. That is advised because we can have a very good understanding of the directions of works in the field and how the people actively working in the field are thinking by reading papers. Only then we can start coming up with our own ideas to experiment upon.
- To develop confidence in the field: Once we start learning about the latest works in the field and we start to develop a good understanding by performing a extensive literature survey, we start developing more confidence to perform more experiments and exploring deeper in the field.
- Most condensed and authentic source of latest knowledge in the field: A reseach paper comes out of days and months, or some times even years of brainstorming of ideas, performing extensive experiments and validating the expected outcomes. The condensed experiments and thoughts is what is best expressed in a research paper that the authors write. Any new content that comes in the field in terms of state-of-the-art works is through research papers. Research papers are the source through which works that push the limits of knowledge in a field come up.
Motivated enough ?
Now that we have attained enough motivations as to why we should read research papers, lets look at how to do literature survey in a domain.
Let’s do it !
Literature survey of a domain
The basic steps to perform literature survey in a field are the following:
- Assemble collections of resources in the form of research papers, Medium articles, blog posts, videos, GitHub repository etc.
- Conduct a deep dive to classify the relevant and irrelevant material.
- Take structured notes that summarises the key discoveries, findings and techniques within a paper.
We shall take Pose Estimation as a example domain and understand each step.
Step 1: Assembling all available resources
First of all we collect all the resources in the form of blog posts, github repositories, medium articles and research papers available in the field, for our case it’s pose estimation. The important question here is, where can we find relevant resources in the field ?
Following are sources where we can find the latest papers and resources:
- Twitter: We can follow top researchers, groups and labs actively working and publishing in our field of domain and be updated with what they are currently working on.
- ML subreddit
- arXiv: Platform where almost all of the papers be it accepted to a conference or not, are uploaded.
- Arxiv Sanity Preserver: Created by Anderj Karpathy which used ML techniques to suggest relevant papers based on previous searches and interests.
- Papers With Code: Redirects to the paper’s abstract page on arXiv, open source implementation of the papers along with links to datasets used and a lot of other analysis and meta information like the current state-of-the art method, comparision of performance of all previous methods in the field e.t.c.
- Top ML, DL Conferences (CVPR, ICCV, NeurIPS, ICML, ICLR etc): Proceedings of the following conferences are a great place to look for latest accepted works in the domains accepted by the conference.
- Google Search
Once listed down all the papers that we wish to look at and all resources we could find be it relevant or irrelevant, a table of this format shown in figure 3 can be prepared and in the first column, all the resources collected can be listed down.
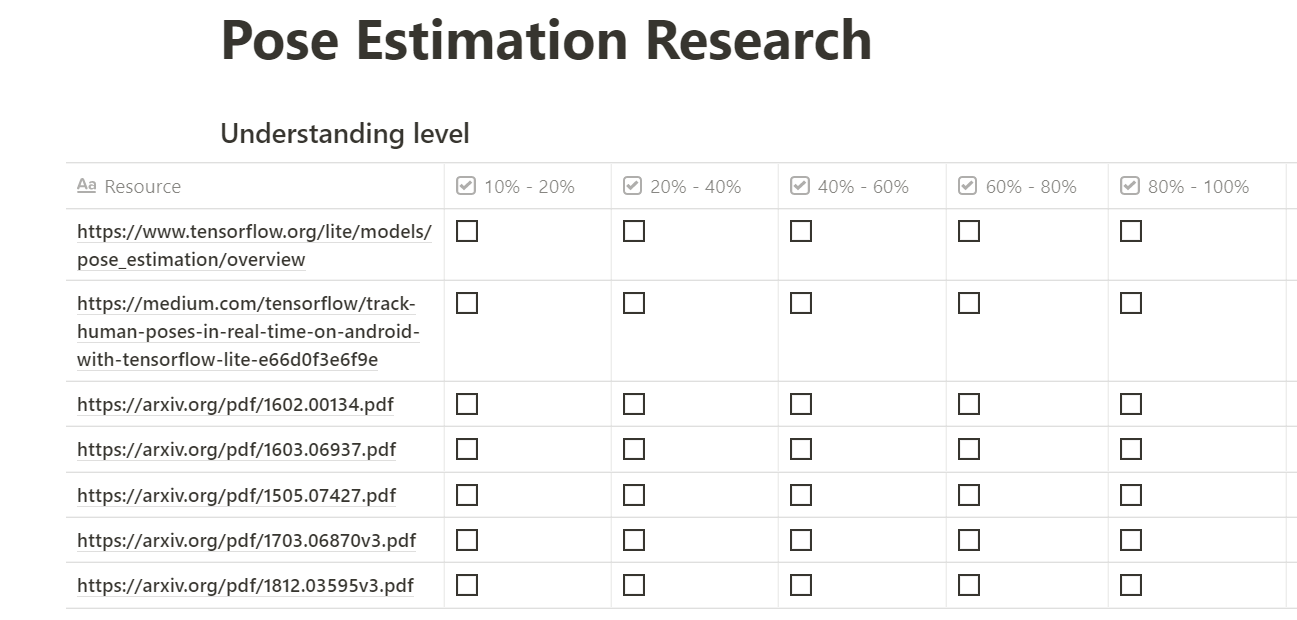
Step2 - Filtering out relevant and Irrelevant resources
Once listed down all the resources and prepared a table like the one shown in figure 3, the next step is to keep the relevant resources and reject the un-necessary ones which may not be directly related to what we want to work on our our research objectives. Follow the following steps to do that:
-
For all the resources listed down, finish 10% of reading of each resource or research paper(first pass reading, we will discuss about it later). If we find it not related to our research objective, we can reject it.
-
If that resurce is related to our objective and is relevant and important to us, do a complete full pass reading over the paper. From the references, if we find any other relevant reference then mark those in the original paper and add them to the list and repeat the same over this new paper or resource now.
So after this, this is what the final table might look like this,

Notice that the 2nd, 4th and 6th resources were important and relevant so we read it in detail but the other oned were not very important or the entire thing was not relevant so we read through some portion of each, whatever was necessary and left the rest.
Such a table can be really useful when we return back to it after some months or years to look for or recall what we have read or the papers we have already looked at and rejected. It helps us to save a lot of time iterating over unnecessary resources and helps us effectively dedicate time to the useful resources.
Step3: Taking Systematic Notes
Once decided on which papers to read, this step depends on the individial about they want to go about taking notes. I personally follow a annotation tool to annotate different sections of the paper according to my comfort. I prepare some flow charts for the entire flow of the paper, write some explaining notes on the paper and summarise each paper to the best of my understanding to a github repository. Here I would Like to give a shoutout to Akshay Uppal who had generously shared his blogpost with his annotated version of the MLP Mixer paper for the Weights and Biases paper reading group. I also wish to share one of my repositories of literature survey when I started working on the field of face spoofing.
Tip: You can use your own ways of making yourself comfortable with the content and taking notes either on github, notion or google docs e.t.c to organise notes.
Organization of a Paper
The majority of papers follow, more or less, the same convention of organization:
- Title: Hopefully catchy ! Includes additional info about the authors and their institutions.
- Abstract: High level summary of the entire work of the paper.
- Introduction: Background info on the field and related research leading up to this paper.
- Related works: Describe the already existing literature on the particular domain.
- Methods: Highly detailed section on the study that was conducted, how it was set up, any instruments used, and finally, the process and workflow.
- Results: Authors talk about the data that was created or collected, it should read as an unbiased account of what occurred.
- Discussions: Here is where authors interpret the results, and convince the readers of their findings and hypothesis.
- References: Any other work that was cited in the body of the text will show up here.
- Appendix: More figures, additional treatments on related math, or extra items of interest can find their way in an appendix.
Finally coming to the most awaited section of the blogpost !
How to read a Research Paper
Now that we know about the different sections of a paper, to understand how to read a paper, we need to understand how a author writes a paper. The intension of an author writing a paper is to get it accepted at a conference. In conferences, reviewers read all the submissions and take a decision based on the work and the scope and expectations of the conference. Let’s have a quick understanding of how the review process works at a very high level.
Warning: Reading a paper sequentially one section after another is not a good option.
In most of the top conferences, there are two submission deadlines: one, the abstract submission deadline. Second, the actual paper submission deadline. So why exactly are there 2 deadlines ? A separate deadline for abstract even before the actual paper deadline definitely implies that abstract is an important part of the paper. But Why is abstract important ?
Note: While Considering to submit for a conference, always note they have 2 deadlines: One, for abstract submission. Second, for the full paper submission.
Every year, a lot of papers get submitted to each conference. The number of submissions are in tens of thousands and it is not feasible to read through all the papers irrespective of how many reviewers the conference can have. So to make the review process easier and quicker, there is a guideline how different sections of a paper must be written and the reviewer also reads in that same pattern.
The first level of review is always the abstract filtering. The abstract is supposed to summarise the entire work briefly and it should clearly state the problem statement and the solution very briefly. If the abstract doesnot satisfy these criterias, the paper gets rejected in this filtering. So the abstract should clearly expain the gist of the work. Hence while reading paper too, the abstract is the place where we can find the gist of the paper clearly and briefly. Hence the abstract is read first to get an overall idea of the entire work. The authors also spend a lot of efforts in getting one figure which gives a visual illustration of the entire approach or a complete flow chart of the entire work. Even this figure contains a gist of the entire method of the paper. The authors try to condense and pack of information about thier work in a single figure.
Note: The abstract is one of the most important sections in a paper and it explains the entire gist of the paper in brief and the most important figure summarises the method adopted.
The reviewers then read the introduction section as it should explain the problem statement in a detailed way and the main proposal of the paper and the contributions. Immediately after this section, once you know what the paper is assuming, the conclusion section tells about the conclusion of the work and whether the assumptions and expectations presented in the introduction are satisfied or not.
Note: The introduction section is supposed to explain the problem statement in detail and the major contributions of the paper. We get to know the intent of the author from this section. The Conclusion section validates the assumptions and propositions given in the introduction through experiments and proofs.
After validating that the assumed propositions have been validated successfully, the method section is seen in detail to see what approach was taken to acheive the goal. In the discussion section, the experiments are explained as to why exactly the proposed method works. This is basically how a reviewer reads a paper and it is the same approach that is to be taken by a reader like us to read a paper.
3 pass approach to read a research paper
A 3 pass approach is taken to read research papers. The content covered in each passes is in sync with the discussion on the review procedure from last section. Following are the 3 passes:
-
First Pass: Read the title, abstract, subsection titles and glance the figures and figure captions.
- Should be able to answer the five C’s (Category, Context, Correctness, Contribution, Clarity)
- Second Pass: Read the Introduction, Conclusion and rest figures and skim rest of the sections(ignoring the details such as mathematical derivations proofs e.t.c.).
- Third Pass: Reading the entire paper with an intention to reimplement it.
Lets go into detail of each section.
First pass
The main intension in the first pass is to understand the overall gist of the paper and have a bird’s eye view of the paper. The intension is to get into the authors intent about the problem statement and his thought process to develop a solution to it. The major sections which should be focused in this pass are the Abstract and the summarising figure and extract the beat possible information of the problem statemant the paper is addressing, solution and the method. The following points are what we cover in the first pass:
- Read through the Title, abstract and the summarising figure.
- Skip all other details of the paper.
- Glance at the paper and understand its overall structure.
-
Try to answer the 5 Cs: After the first pass, we should be able to answer the folling 5 things about a paper:
- Category: Which category of paper is it, whether its an architecture paper, or a new training strategy, or a new loss function ar is it a review paper e.t.c.
- Context: What previous works and area does it relate to. E.g - while Reading the DenseNet paper, it falls in the context of architectural papers and it falls into the resnet kind of networks architecture context.
- Correctness: How correct and valid is the problem statement that the problem is addressing and how correct does the proposed solution sound. Honesty this can’t be totally jugded from just the first pass completely as a complete answer and unserstanding of correctness would need looking at the conclusion section, but try to judge as best to your knowledge about the correctness.
- Contribution: What exactly is the contribution of the paper to the community. Eg - the resnet paper contributed the resisual block and skip connection architecture.
- Clarity: How clearly does the abstract explain the problem statement and their approach towards it.
- Based on our understanding of first pass, we decide weather to go forward or stop with the paper for a detailed study into further passes.
While discussing about literature survey, I mentioned about the 10% study on each resource to figure out if that resource is relevant to us. The 10% basically meant doing a first pass over all the resources.
Note: After the first pass, we understand the gist of the paper and get into the intent and thinking of the author.
Second Pass
After getting an overall gist of the paper after the first pass, we headon to the 2nd pass of the paper. The main intention of this section is to understand the paper in a litle more detail in terms of understanding the problemstatement in detail, validating if the paper validates the propositions it made to solve, understand the method in detail and understand the experiments well through the discussion section. The following is what we do in a 2nd pass:
- Reading more in depth through the Introduction, conclusion and other figures.
- Literature survey, Mathematical derivations, proofs etc and any thing that seems complicated and needs extended study from the references or other resources are skipped.
- Understand the other figures in the paper properly, develop intuition about the tables, charts and analysis presented. These figures contain a lot of latent information and explain a lot more things. so it is important to extract the maximum understanding from the figures
- Discuss the gist of the paper and main contents with a friend or colleague.
- Mark relevant references that may be required to be revisited later.
- Decide weather to go forward or stop based on this pass.
After the 2nd pass, we have a good understanding of the paper in terms of the method of the paper, experiments and conclusions out of them. Depending on understanding from it, we go on to the next pass.
Tip: A second pass is suitable for papers that you are interested but not from your field or is not directly related to your research goal.
Third Pass
After getting a more indepth understanding of the paper after a second pass, we go on to the final pass of reading which is the most detailed pass over the paper. This pass is only for papers which are most important for the research objective and are directly related to the objective we are working on. Following are the key points for a third pass:
- Reading with an intention to reimplement the paper.
- Consider every minor assumption and details and make note of it.
- Recreate the exact work as in the paper and compare it with original work
- Identify, question and Challenge every assumption in the paper.
- Make a flow chart of the entire process considering each step.
- Try deriving the mathematical derivations from scratch.
- Start looking at the code implementation of various components if an open source implementation is available else try to implement it.
After a third pass, we should be knowing the paper inside out including every minor assumption and detail in it along with a clear understanding of the implementation and good understanding of the hyperparameters of each experiment perform and presented in the paper. After all the passes we can claim to have a clear understanding of the research paper.
To validate our understanding of the paper, there are a few generic question we can try to answer about the paper and if we are able to answer these questions, we have more or less understood the paper to a level where we can use it for our own research as per our requrement and our objective.
Important Questions to answer
-
What problems statement does the paper address?
- Answer to this can be found in brief in the abstract section and in detail in the Introduction section.
-
Is the problem statement a relevant one?
- self assessment of the problem statement.
-
What do the authors of the paper aim to accomplish, or perhaps want to achieve?
- Answer to this can be found from the Introduction section.
-
If a new approach/technique/method was introduced in a paper, what are the key elements of the newly proposed approach?
- Answer to this can be found from the Introduction section section in the contributions section and also the methoda section.
-
What is the main approach in the paper, what experiments have the authors performed and how well do the experiments results validate the conclusions?
- Answer to this is the entire method sections and discussions section.
-
What are the main conclusions of the paper?
- Answer to this is the entire conclusion section.
-
A few personal questions:
-
What content within the paper is useful to you?
- Many a times a paper has many key elements which they put together to solve their problem statement. At times your problem statement maybe just a subset of the papers problem set or viceversa or a particular element of the paper may be solving some problem youa re interested into and not the others. So it is important to figure out what part of the paper is useful to you.
-
What other references do I need to or want to follow?
- Some sections of the paper may seem complicated or you may need to look at some previous references to understand this work completely. Also you might find some papers from the citations which are also useful to your research. So figure out the necessary references and refer to them.
-
What content within the paper is useful to you?
Being able to answer all these question to the ebst of our understanding and abilities validates our level of understanding of the paper. These questions can also be attempted after the 2nd pass itself and we can check our understanding after the 2nd pass itself. Then again try to answer them after a 3rd pass and judge if our understanding has improved over the 2nd pass or another pass with deeper exploration is again needed.
Tip: Nothing teaches better than implementing the entire thing from scratch and experimenting and comparing the results with original results. Even if a open source implementation is available, experimentation with the opensource code and coming up with own tweeks to the code, running different hyperparameters can improve our understanding a lot.
Conclusion
Finishing with a important note that reading papers is a skill that can be learnt with consistency over a long period of time. It is not a sprint but a marathon and demands lot of patience and consistency.
I hope I have been able to justify the title of the blog post and explain everything in detail about how to do literature survey of a domain and how to read an ML / DL research paper. Incase I missed out on anything or you have any other comments, reach me out @SaiAmritPatnaik
Thank you !