Lets Keep Classification Simple !
A post on importance of baseline models and developing a baseline model for MNIST digits classification.



- Baseline Model
- Baseline for MNIST data classification
- Setup Fastai and Necessary Imports
- Loading Dataset
- Approach for the Baseline
- Baseline Algorithm
- Preparing the training and testing tensors
- Computing the Mean Image for each class
- Computing the similarity
Whenever it comes to image domain task like classification, segmentation etc, the first thing that comes to the mind is of a conplex model like Convolutional Neural Network which performs a heavily complicated operation over the image to extract meaningful features and then perform the required task using the features.
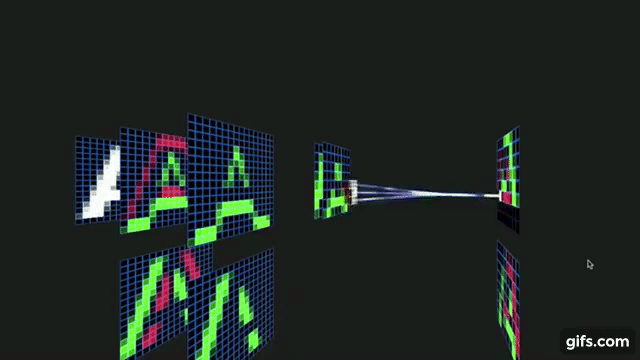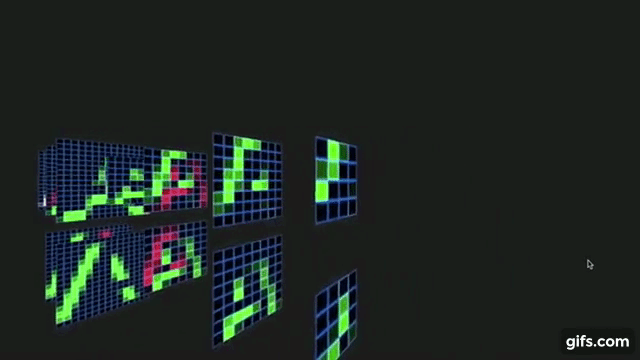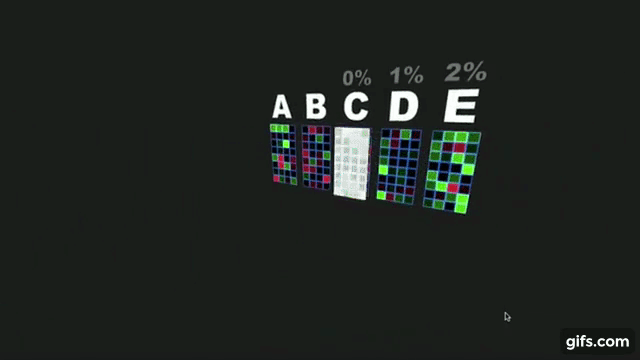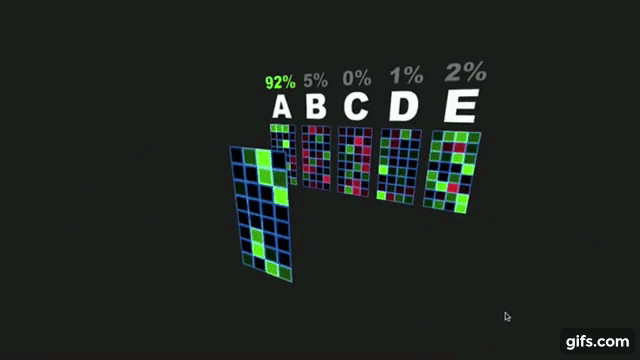
Rather than involving a complicated model with a hope that a complex model is bound to perform beat on the data and give us almost perfect performance, its always wise to come-up with a very simple algorithm based on visual observation or simple statistical studies over the given image data to get a descent baseline performance and then build upon it till we reach a saturation of performance.
Baseline Model
A simple model which you are confident should perform reasonably well. It should be very simple to implement, and very easy to test, so that you can then test each of your improved ideas, and make sure they are always better than your baseline. Without starting with a sensible baseline, it is very difficult to know whether your super-fancy models are actually any good.
Baseline for MNIST data classification
MNIST is the most basic dataset in computer vision. It itself and its varients serve as baseline datasets for testing most of the new approaches that researchers come up in vision.
In this article, we shall try to build a very simple decision policy to classify a give test image into one of the digit classes without involving any convolution operation or complicated feature extraction and classifier.
Setup Fastai and Necessary Imports
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastai.vision.all import *
from fastbook import *
matplotlib.rc('image', cmap='Greys')
path = untar_data(URLs.MNIST)
training_paths = (path/'training').ls().sorted()
test_paths = (path/'testing').ls().sorted()
Let's have a look at some sample images from each class to understand the data and design a baseline algorithm.
sample_images = [Image.open(training_paths[i].ls()[0]) for i in range(10)]
show_images(sample_images, nrows=1)

Approach for the Baseline
One good approach to creating a baseline is to think of a simple, easy-to-implement model. The simplest thing that comes to the mind on looking at the images is that:
- Each number has a characteristic shape and pixel distribution. Every other image of the same number should ideally possess similar characteristics and pixel distribution.
- If we can come up with a representative for each class that posseses characteristics of maximum members of the class and then simply compare every unknown test image with each of this representative and classify it to that class, whose representative is most similar to it.
- Similarity can be defined in terms of pixel wise difference which takes into account pixel distribution into the similarity metric.
- Finally the most basic representative for a class can be its mean image.
Baseline Algorithm
- Prepare training data by stacking up all images of a particular digit into one tensor.
- Find the mean image for each of these digits.
- Loop over all the test image and find its distance from each of the mean image and consider its label to be the one with the minimum distance.
- Calculate accuracy of this method.
Preparing the training and testing tensors
training_data = []
for pth in training_paths:
training_data.append(torch.stack([tensor(Image.open(o)) for o in pth.ls()]).float()/255)
test_data = []
for pth in test_paths:
test_data.append(torch.stack([tensor(Image.open(o)) for o in pth.ls()]).float()/255)
mean_images = [data.mean(0) for data in training_data]
show_images(mean_images, nrows=1)

total = 0
correct = 0
for i in range(10):
total += test_data[i].shape[0]
predict = tensor([tensor([F.mse_loss(test_data[i][im],mean_images[mean]).sqrt() for mean in range(10)]).argmin() for im in range(test_data[i].shape[0])])
correct += (predict == i).sum()
print('Accuracy of simple model is: {:.2f} %'.format(correct/total*100))
Notice that just using mean image and L2 distance, we can acheive a baseline performance of 82.03% on MNIST data. This is probably the most simple classification strategy that could be thought of. So any model that performs worse than this should not be accepted.
It is really interesting to note that such a simple approach performs descent on a image data which is fairly complicated. The conclusion is to always start with simpe ideas and establish a baseline model and then build upon that idea and improve performance from the benchmark performance acheived by the baseline model.